CAM Introduction (Chinese)
1. 为什么CAM
CAM 全称为Classification Activation Map,分类激活图, 是一种比较老(发源于2017年)的神经网络学习可视方法,一般也被认为是对神经网络进行解释的工具。当然,做为一个实用主义的人,这一堆不说人话的东西下来有点懵,咱就简单粗暴一点。某君训练了一个牛逼的神经网络,分类任务什么的准的不得了,那这时候问题就来了。 What the hell your model learned? 当然这问题会把也问懵,因为大部分人都想着黑猫白猫,逮着老鼠就是好猫,你管我怎么逮呢?可是有时候,我不知道你是怎么逮的,我怎么敢让你逮呢? 踩着花花草草不要紧,万一你是蒙的,万一你是连房子一起拆了就不好了吧? 所以,这种时候就需要一个东西告诉我们你的神经网络到底学了什么。那就是CAM。
这篇小文章主要讲两种最早的技术,CAM 和grad-CAM, 有需要的话,请上幼儿园大班,这不是我们小班教的东西。CAM 和grad-CAM 都是基于梯度的方法,当然也有不基于梯度的方法,详情请Google。
2. 技术简介
首先,容我先限定一下,而我所讲的内容目前仅谈论基于卷积神经网络(CNN)进行特征提取的模型,transformer什么的也已经超纲了。
2.1 基本思路
如果熟悉CNN的话,我们知道CNN的本质是提取特征,而且是从局部到全局的提取,hierarchically,(感觉这一个单词省了好多文字)。这时候不得不放一张经典的图了。

可以看到,从底层到顶层,CNN学的就是从边边角角到具体化的凝结物,比如车轮什么的,当然还有一些好像神秘学的符号。 那么,我们的想法就是这些特征的某种联系决定了我们分类的结果。为了方便起见,我们将这种联系近似为线性加权, 但是特征图是高维的,预测的种类是一个标量,中间需要一个函数的转换,因此我们将这种关系表征如下。
\[y_{pre} =f \big(a_{1}f_{1}+a_{2}f_{2}+ \ldots \ldots +a_{n}f_{n}\big) =f \big( \sum_i^n a_{i}f_{i} \big)\]其中,y_pre 是指预测出的归属种类的值,直白一点,就是你在多个种类的分类中给出的最大概率了。a是权重系数,F 是特征图,下标n是特征图的排序,比如你最后一层生成了512个特征图,那n就是512。f 是张量转标量过程中的函数过程。 机智的你一定想到了接下来的公式。
\[y=g\left(image\right)=f\left(\sum_i^n a_{i}f_{i}\right)\] \[image\propto\sum_i^n a_{i}f_{i}\]什么意思呢,百因必有果,你的报应就是我,预测的结果是某张图的宿命,这个宿命联系呢,我们用函数g表示。多次一举的说,图片和其特征图之间肯定也是联系的(好像我公式推导逻辑上本末倒置了,唉,就这样吧)。你说巧不巧,图片是图,我的特征图最后加权一下也是图,如果把特征图当蒙皮给原本图片一罩,我不就知道我的模型的目光到底 注视 哪里了吗? 是不是很朴素的想法? 什么?特征图和原始图片尺寸不一样?简单,咱们reshape一下,给他当海贼 王路飞 拉一拉就好了,很exciting啊。那问题就剩一个了,谁告诉我那些特征图权重去哪领啊?
2.2 CAM
至于权重问题,CAM 给出的答案很粗暴——咱们再算一遍!
具体的操作如下图所示。
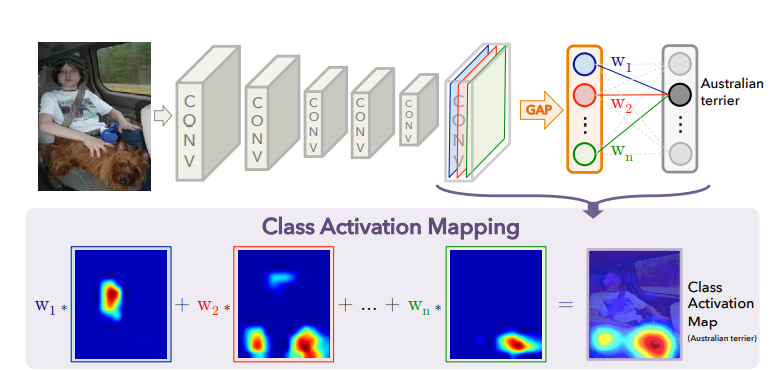
其实图已经很直观了——欲练此功,必先自宫!(辟邪剑法,暴露年龄了) 你不是用网络做了分类了吗?任何一个CNN 都能分解成特征提取(CNN) 和分类器(classifier,一般是全连接层)对不对? 把你的分类器删了,添加一个global average pooling (GAP),这个GAP 的作用就是把你的特征图变成一个标量,那么你有512个特征图就是512个标量了,然后针对每一个类别咱们直接乘以512个权重,让应该归属的类别的点积值在所有分类的点积值中最大,其实就是一个全连接层做分类器。至于怎么搞这512个权重,很简单啊,再训练一遍呗,只有一点切记,我们想看的是原有模型的表现,不是这个辅助模型的特征表现,所有不能够动之前的CNN的权重,因此就是fine-tuning一下,把之前训练好的cnn权重全freeze就好了,只训练全连接层就好了。训练完之后,权重和特征图一相乘,便胜过人间无数。边可以看到特征的重点在哪,一拉伸,一覆盖,我们就知道这模型到底是看腿还是看脸。 等等,这些东西是不是有些熟悉? 没错,attention is all you need,这就是做了个self-attention啊,还记不记得我前面标粗了一个关注,小彩蛋送给大家。
2.3 Grad-CAM
CAM这套东西啊, 好归好,就是麻烦,我好不容易训练一个模型,你还让我拆了装装了拆,麻烦!另外呢,有时候吧,我的模型比较特别,比如说一些meta learning的模型,比如matching network或者triplet,我的训练逻辑和分类逻辑比较“怪”,你这套男人练的辟邪剑法,我根本都没法那啥,你让我怎么练? 那么就有了第二种改良版的方法——grad-CAM[3],这个就比较泛化了,万金油一些。你不是要权重吗?把最开始的公式拿过来,贴下面。
\[image\propto\sum_i^n a_{i}f_{i}\]你给我解释解释,什么叫tm的tm的权重?初中老师已经告诉你了,直线的导数就是斜率,就是那个未知数前面的a? 这不就结了吗。倒数这东西一个backpropagation 不就求出来了吗,你再扒拉出来就行了。问题呢,有一个。特征图上的每一个像素都被求了导,我最后每个特征图上得到了一个导数矩阵,这咋办,不是个标量。好办啊,你global average pooling做的了初一,兄弟我做的了十五,很快的哈,我给我这个导数矩阵也做一次不久结了吗, 翻译成人话就是求这些倒数的平均数就行了。
\[image\propto\sum_i^n a_{i}f_{i}=\sum_i^nmean(\frac{\partial y_{pre}}{\partial f_{xyi}})f_{i}\]其中呢,x,y 就是特征图上的坐标了。其余的套路呢跟CAM 是一样的。好像忘了重要的事情,记不记得CAM 里面的A 是activation 激活,什么意思呢? 因为CNN 里的非线性是靠relu(及其变种)实现的,凡是小于0的值,过了relu都被设成了0,因此,小于0的特征值是毫无意义的,所以我们的加权特征图现在还不能直接用,我们也让它过一遍relu,只留下大于0的部分。 CAM 的优势很明显,那就是不用改变网络结构,一些异种网络,你只要知道该对谁做导数,也是可以用的,没那么多限制。
2.4 一点点拓展
为什么要用最后一层特征图? 还记得我们之前说特征图是从局部到全局,因此,我们的蒙皮是要全局的蒙皮,而不是局部的蒙皮。那根据我的理解,如果这样的话,网络很深的话,可以用倒数第二层,第三层。因为有时候最后一层特征图可能就是个3*3的大小,你就是拉开了也很难看到什么东西。
Grad-CAM是不是让你想起了什么东西? 对,一阶泰勒展开,既然它是一阶泰勒展开来逼近重要性,我就可以用二阶泰勒展开来逼近,那三阶,四阶,。。。。这不就是grad++ CAM的做法,有兴趣的可以上网搜。
除了理解网络到底学了啥,是不是看对了地方。CAM 还可以用于做segmentation的任务,毕竟你告诉了我重点在哪,那基本就是目标物体所在地了,当然这属于附加产品,比较weak。
CAM 是针对Classification的,那regression呢? 我觉得想法差不多,感兴趣的网上搜一搜.
Reference
[1] Zeiler MD, Fergus R. Visualizing and understanding convolutional networks. Lect Notes Comput Sci (Including Subser Lect Notes Artif Intell Lect Notes Bioinformatics) 2014;8689 LNCS:818–33. https://doi.org/10.1007/978-3-319-10590-1_53.
[2] Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning Deep Features for Discriminative Localization. CVPR 2016;2004:M1–6. https://doi.org/10.5465/ambpp.2004.13862426.
[3] Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int J Comput Vis 2017;128:336–59. https://doi.org/10.1007/s11263-019-01228-7.